
Scaling both data and model size is widely recognized as a key driver of improvements in artificial intelligence. However, the research and industry communities have limited experience in effectively scaling extremely large models—whether dense or Mixture-of-Experts (MoE) architectures. Many crucial insights into this process were only recently revealed with the release of DeepSeek V3.
In parallel, we have been developing Qwen2.5-Max, a large-scale MoE model trained on over 20 trillion tokens and further refined through Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). Today, we are thrilled to share its performance results and announce the availability of the Qwen2.5-Max API on Alibaba Cloud.
We invite you to experience Qwen2.5-Max firsthand on Qwen Chat!
Performance Evaluation
We assess Qwen2.5-Max against leading proprietary and open-weight models across key benchmarks that are highly relevant to the AI community. These benchmarks include:
- MMLU-Pro – Evaluates knowledge retention through college-level questions.
- LiveCodeBench – Measures coding proficiency.
- LiveBench – Provides a comprehensive assessment of general capabilities.
- Arena-Hard – Simulates human preference evaluation.
Our analysis covers both base models and instruct models, highlighting their respective performance scores.
To begin, we compare the instruct models, which are optimized for downstream applications such as chat and coding. We present the performance of Qwen2.5-Max alongside cutting-edge models, including DeepSeek V3, GPT-4o, and Claude-3.5-Sonnet.
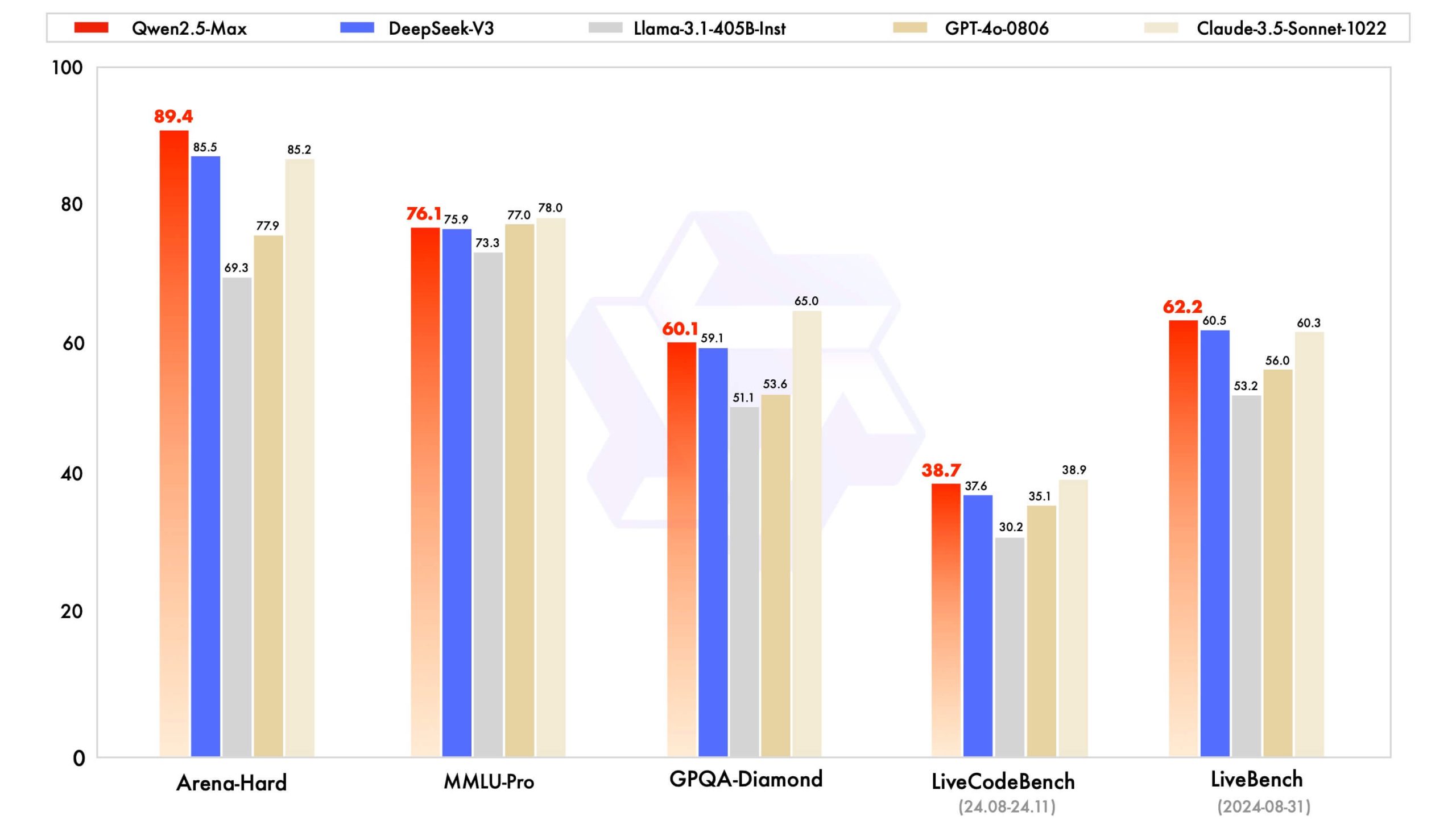
Qwen2.5-Max surpasses DeepSeek V3 in key benchmarks such as Arena-Hard, LiveBench, LiveCodeBench, and GPQA-Diamond, while also delivering strong, competitive results in other evaluations, including MMLU-Pro.
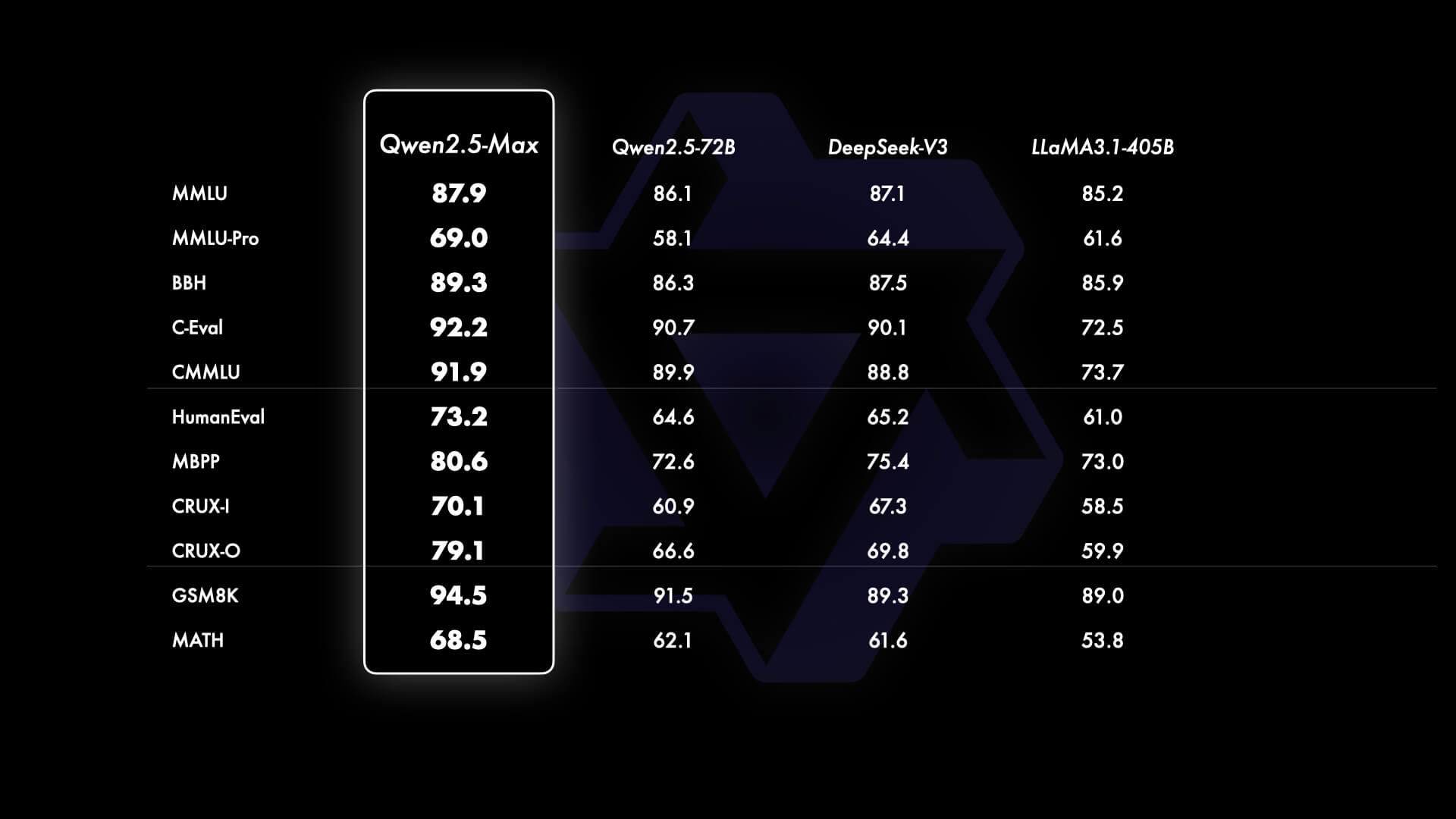
For base model comparisons, access to proprietary models like GPT-4o and Claude-3.5-Sonnet is unavailable. Therefore, we benchmark Qwen2.5-Max against:
- DeepSeek V3 – A leading open-weight MoE model.
- Llama-3.1-405B – The largest open-weight dense model.
- Qwen2.5-72B – One of the top open-weight dense models.
The results of this comparison are detailed below.
Qwen2.5-Max API Access
The Qwen2.5-Max API (model name: qwen-max-2025-01-25) is now available. To get started, follow these steps:
- Register for an Alibaba Cloud account.
- Activate the Alibaba Cloud Model Studio service.
- Generate an API key via the Alibaba Cloud console.
Since Qwen APIs are OpenAI-API compatible, you can seamlessly integrate them using the standard OpenAI API workflow. Below is a Python example demonstrating how to interact with Qwen2.5-Max:
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-max-2025-01-25",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Which number is larger, 9.11 or 9.8?'}
]
)
print(completion.choices[0].message)
Future Directions
Scaling both data and model size not only drives advancements in AI intelligence but also reflects our commitment to pioneering research. Our ongoing focus is on enhancing thinking and reasoning capabilities in large language models through scaled reinforcement learning. This research paves the way for models to push beyond human intelligence, unlocking new frontiers of knowledge and understanding.
Citation
If you find Qwen2.5 useful, please consider citing our work:
@article{qwen25,
title={Qwen2.5 Technical Report},
author={Qwen Team},
journal={arXiv preprint arXiv:2412.15115},
year={2024}
}


{kind=link}